
设置语言模型
实际上,Rime 是自带一个语言模型的,也就是平时我们所说的“八股文”,也就是在词典设置时候,可以选择的配置参数:
---
name: rime_mint # 注意name和文件名一致
version: "2024.02.11"
sort: by_weight
use_preset_vocabulary: false # 是否启用预设的“八股文”模型
# 此处为 输入法所用到的词库,既补充拓展词库的地方
# 雾凇拼音词库,由Github Robot自动更新
import_tables:
- dicts/custom_simple # 自定义
- dicts/rime_ice.8105 # 白霜拼音 常用字集合
- dicts/rime_ice.41448 # 白霜拼音 完整字集合
- dicts/rime_ice.base # 白霜拼音 基础词库
- dicts/rime_ice.ext # 白霜拼音 扩展词库
- dicts/other_kaomoji # 颜文字表情(按`VV`呼出)
- dicts/rime_ice.others # 雾凇拼音 others词库(用于自动纠错)
# 20240608 Emoji完全交友OpenCC,不再使用字典作为补充
# - dicts/other_emoji # Emoji(仅仅作为补充,实际使用一般是OpenCC生效)
...但是,rime 自带的“八股文”,实际上也是 Lite 版本:https://github.com/rime/rime-essay。所以,实际的效果有限,好在我们可以自定义语言模型。
这里推荐大家可以使用 万象拼音模型。
使用效果
首先,我们看看没有安装万象拼音模型的效果:
如果我们想输入:渐渐地就不在意了,对应码字 jian jian de jiu bu zai yi le。如果没有万象拼音模型,可能会出现:
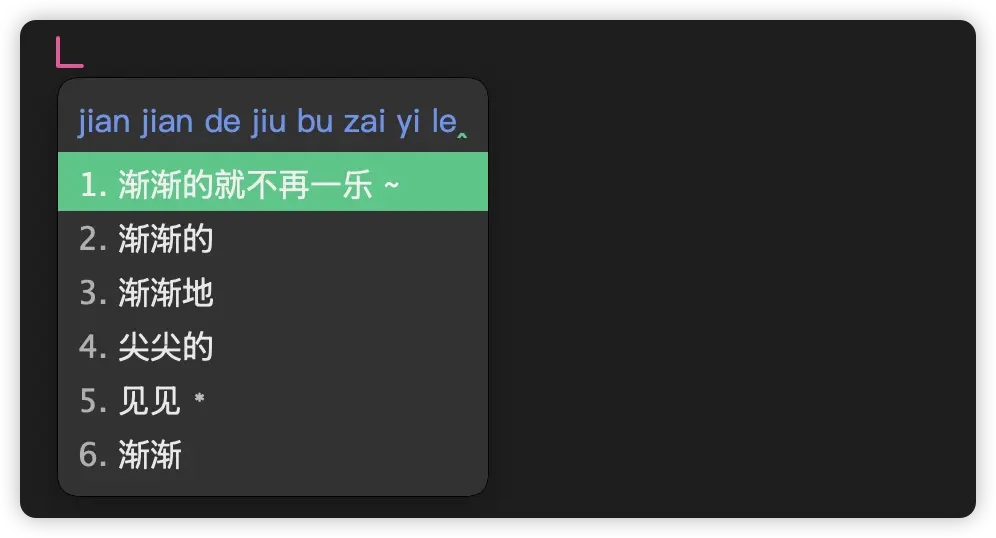
(「不/在意/了」被理解成了「不再/一乐」)
使用了万象拼音模型后,效果如下:
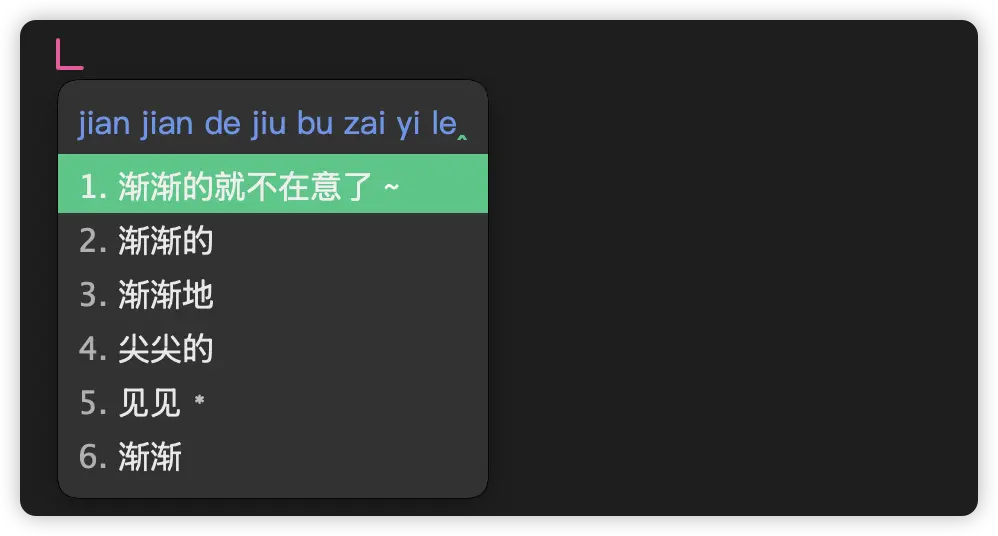
也就是对于句子和词组的识别更加准确。
安装万象模型
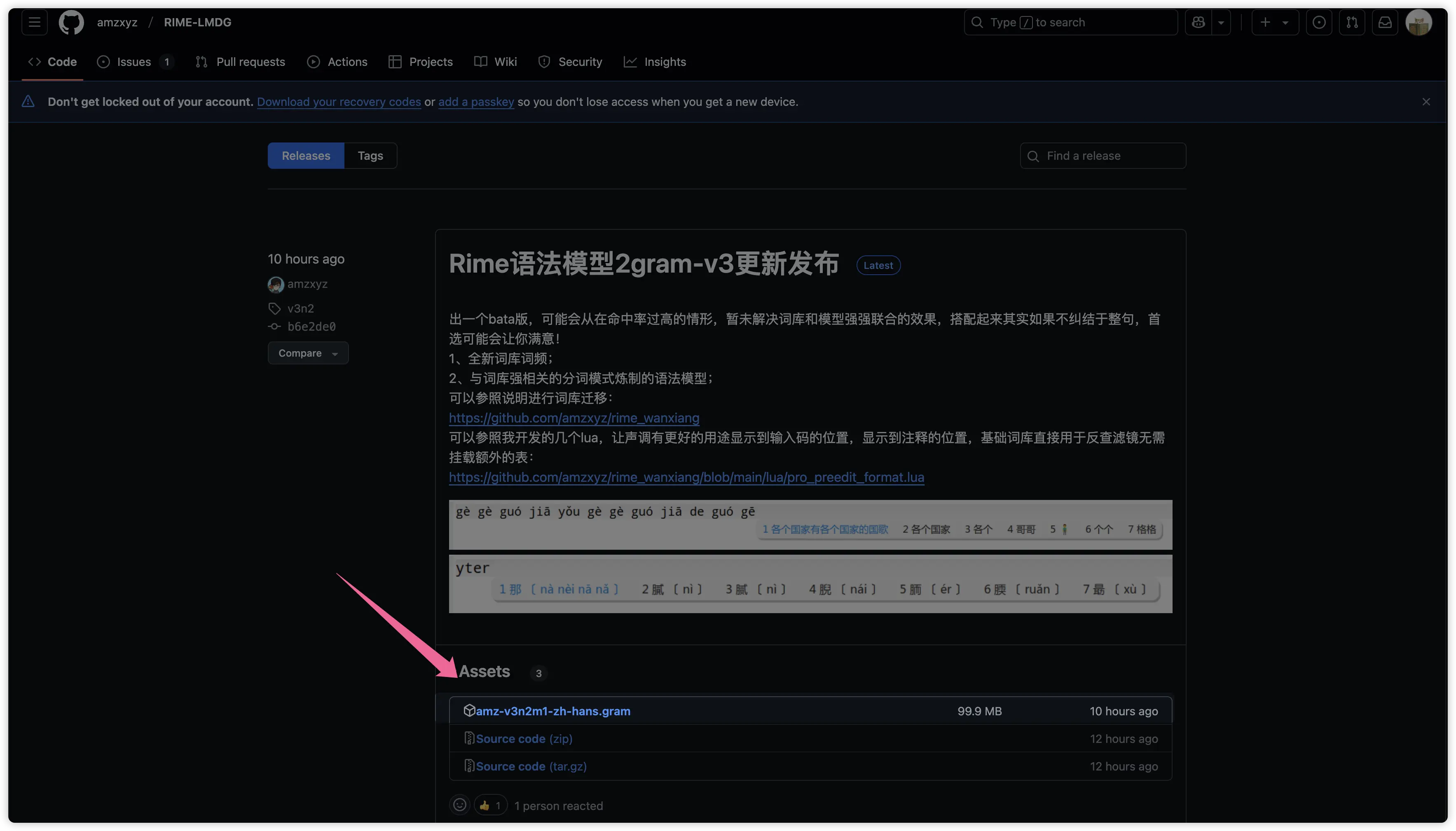
安装万象拼音模型,需要下载对应的文件,然后将其放入 Rime 的配置目录内。首先打开万象拼音模型的 Github 仓库发布地址,下载最新的版本:
镜像加速信息
如果你无法访问 GitHub,或者下载过慢;那么可以使用薄荷提供的镜像下载(感谢 CNB 提供的算力和存储支持;自动同步最新版本 万象模型 :
之后,移动配置文件到 Rime 的配置目录内,比如 macOS 鼠须管的配置目录:$HOME/Library/Rime/:
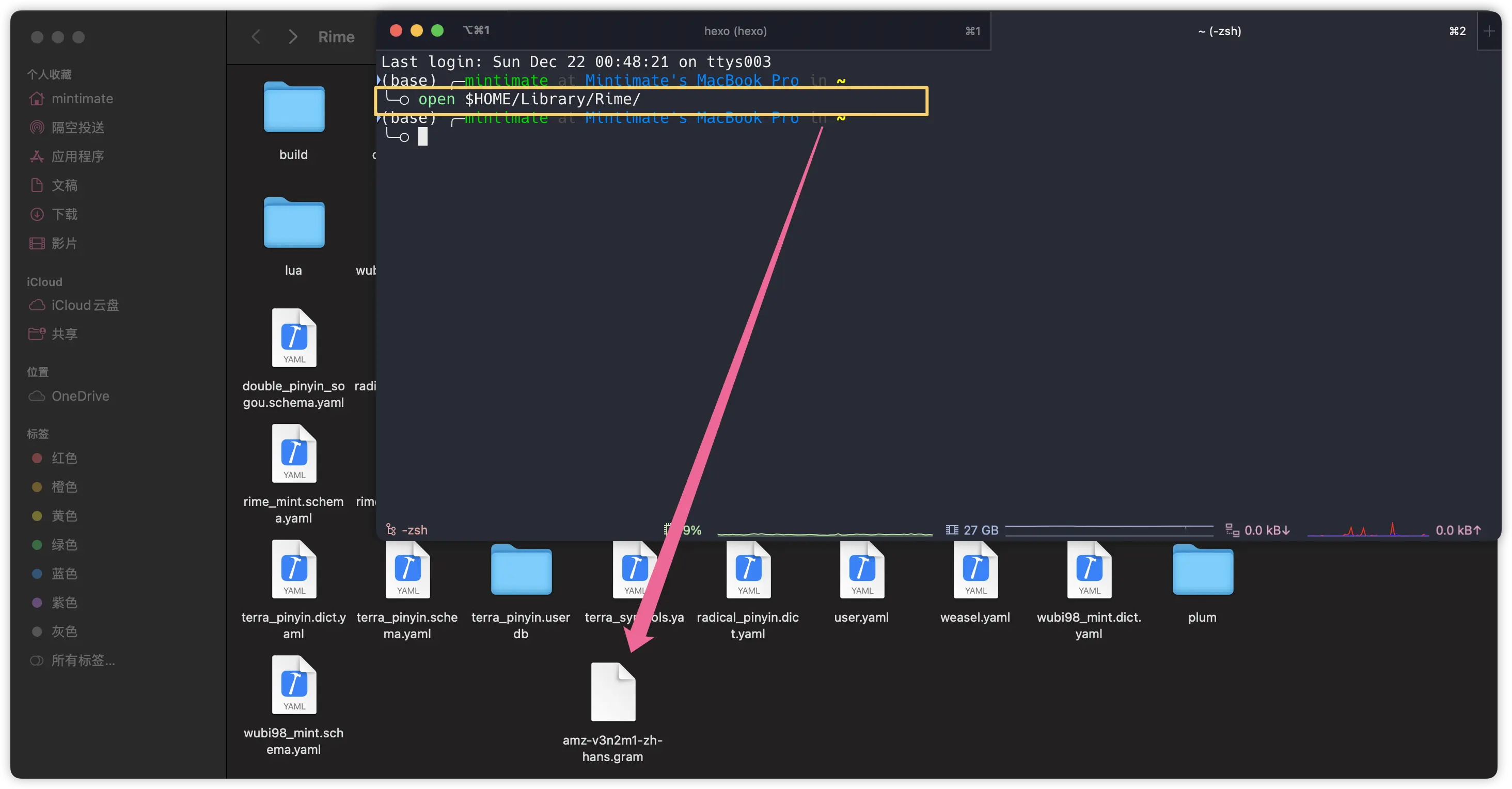
这里,我们下载的语言模型文件是:wanxiang-lts-zh-hans.gram,所以我们如果要在薄荷全拼(rime_mint)中使用,可以在rime_mint.custom.yaml中添加:
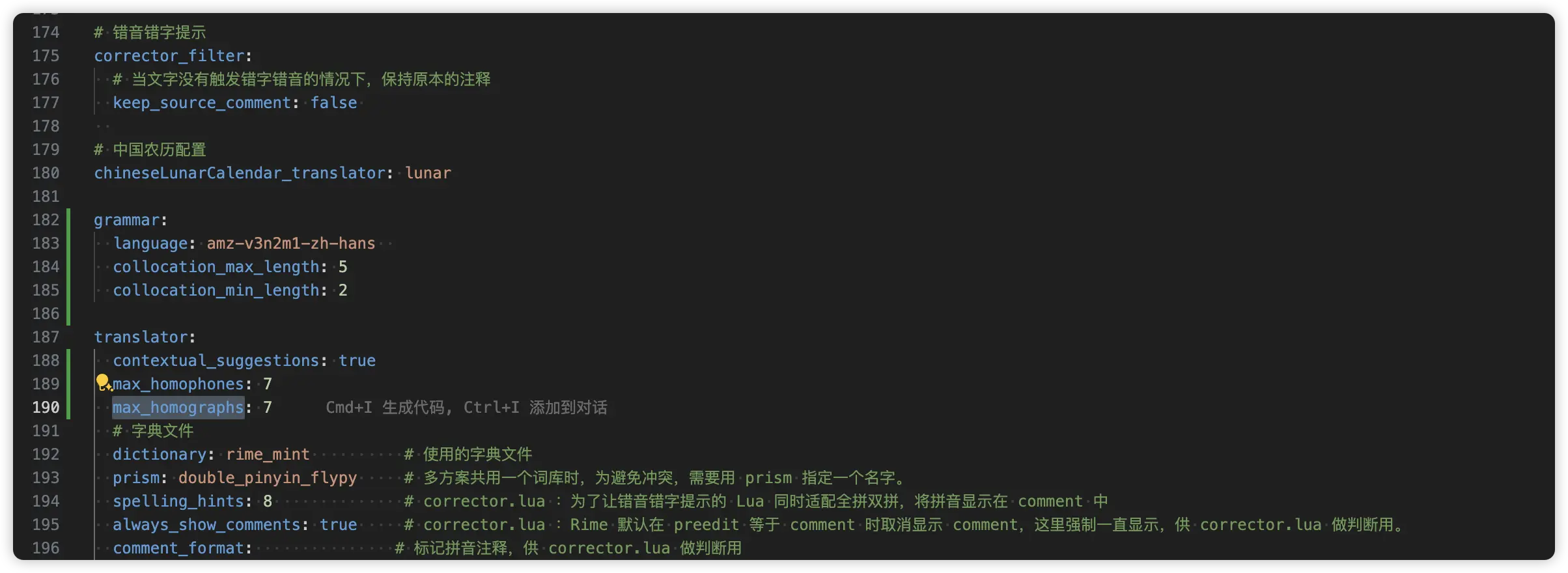
参数说明
自 2026-05-21 起,grammar 参数已更新。由万象作者基于实际语料标注和调试后,更新了 collocation_penalty、non_collocation_penalty、rear_penalty 三个参数,以获得更佳的句子与文字正确率。
patch:
# 语言模型
"grammar/language": wanxiang-lts-zh-hans
"grammar/collocation_max_length": 8
"grammar/collocation_min_length": 2
"grammar/collocation_penalty": -16
"grammar/non_collocation_penalty": -8
"grammar/weak_collocation_penalty": -100
"grammar/rear_penalty": -20
# translator 内加载
"translator/contextual_suggestions": true
"translator/max_homophones": 7
"translator/max_homographs": 7最后,重新部署即可。
如果你想直接修改 rime_mint.schema.yaml,可以直接这样修改:
使用建议
建议喜欢打长句的小伙伴,可以加载万象拼音模型,这样对于长句的识别更加准确。