
Setting Language Model
In fact, Rime comes with a built-in language model, which we usually refer to as the "八股文". This can be configured in the dictionary settings with the following parameters:
---
name: rime_mint # 注意name和文件名一致
version: "2024.02.11"
sort: by_weight
use_preset_vocabulary: false # 是否启用预设的“八股文”模型
# 此处为 输入法所用到的词库,既补充拓展词库的地方
# 雾凇拼音词库,由Github Robot自动更新
import_tables:
- dicts/custom_simple # 自定义
- dicts/rime_ice.8105 # 白霜拼音 常用字集合
- dicts/rime_ice.41448 # 白霜拼音 完整字集合
- dicts/rime_ice.base # 白霜拼音 基础词库
- dicts/rime_ice.ext # 白霜拼音 扩展词库
- dicts/other_kaomoji # 颜文字表情(按`VV`呼出)
- dicts/rime_ice.others # 雾凇拼音 others词库(用于自动纠错)
# 20240608 Emoji完全交友OpenCC,不再使用字典作为补充
# - dicts/other_emoji # Emoji(仅仅作为补充,实际使用一般是OpenCC生效)
...However, the built-in "八股文" in Rime is actually a Lite version: https://github.com/rime/rime-essay. Therefore, the actual effect is limited, but fortunately, we can customize the language model.
Here, we recommend using the RIME-LMDG.
Usage Effect
First, let's see the effect without installing the RIME-LMDG Model:
If we want to input: 渐渐地就不在意了, corresponding to the code jian jian de jiu bu zai yi le. Without the RIME-LMDG Model, it might appear as:
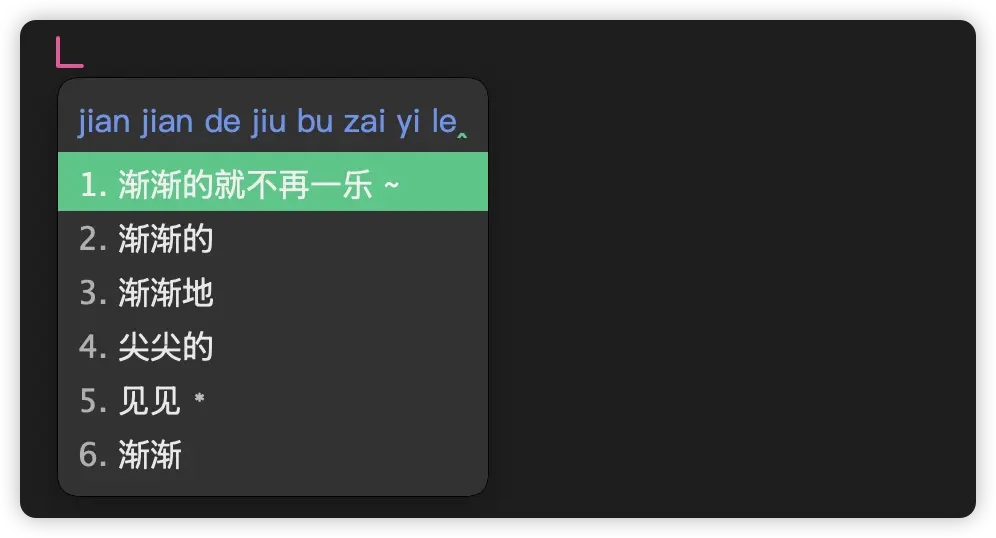
("不/在意/了" is understood as "不再/一乐")
After using the RIME-LMDG Model, the effect is as follows:
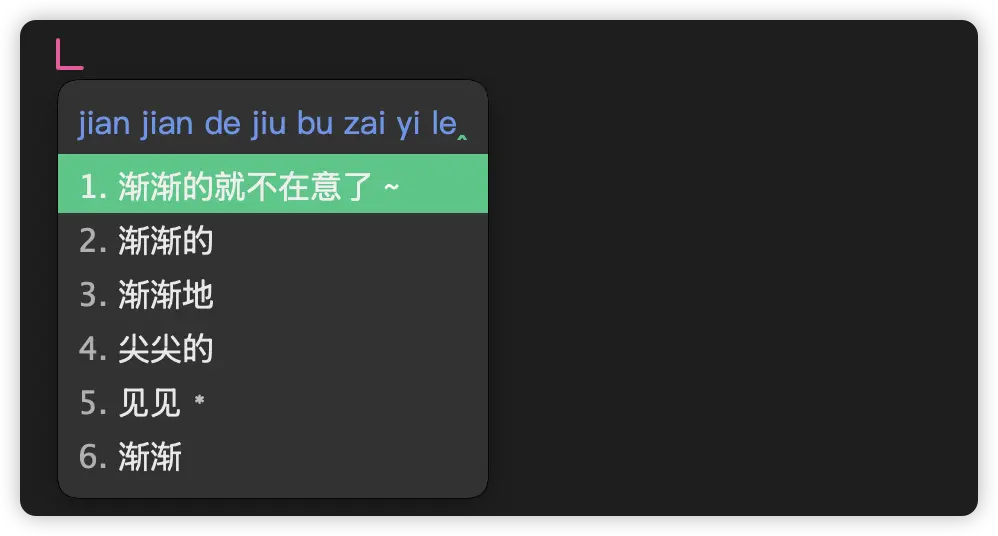
That is, the recognition of sentences and phrases is more accurate.
Installing RIME-LMDG Model
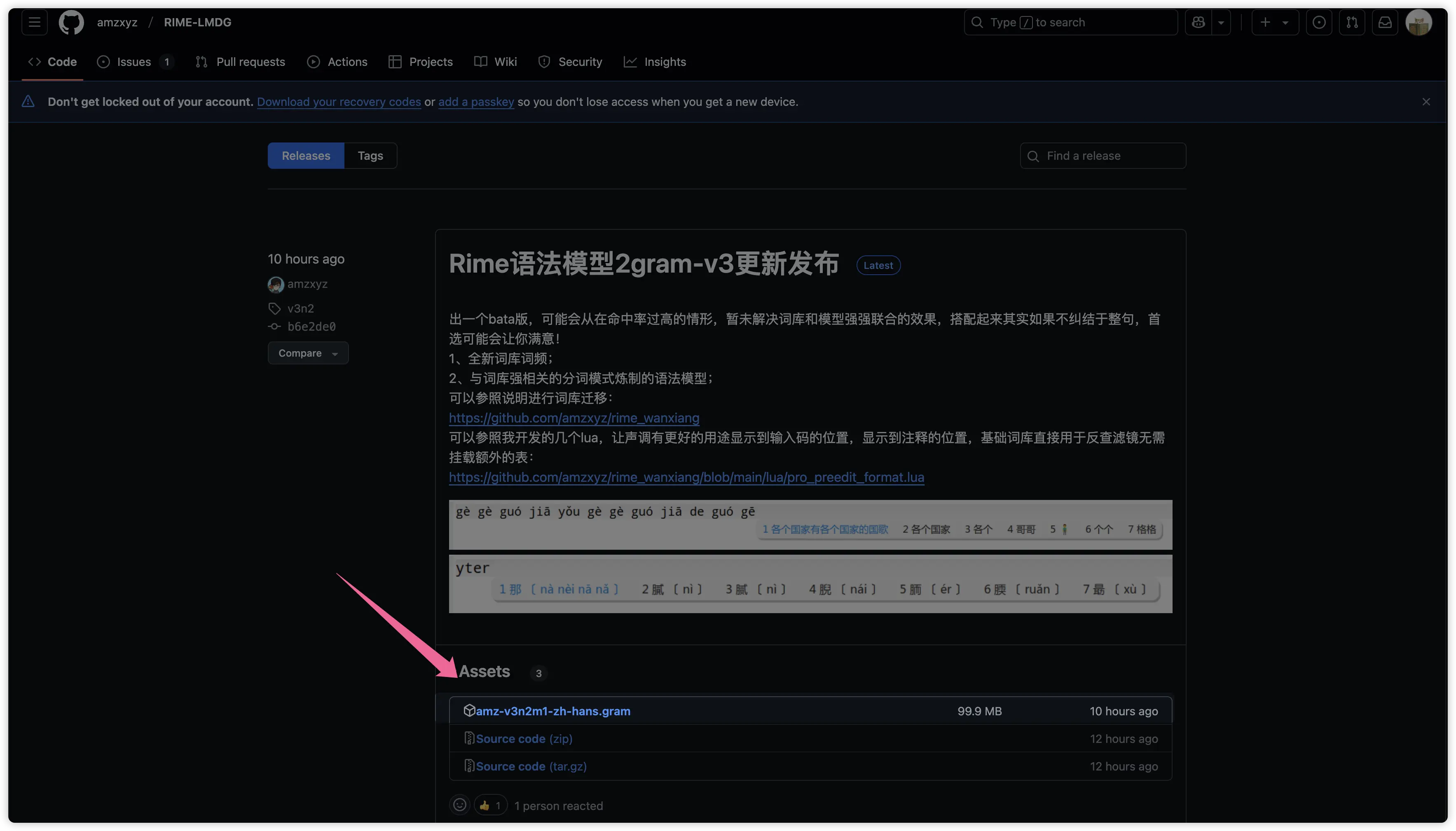
To install the RIME-LMDG Model, you need to download the corresponding files and place them in the Rime configuration directory. First, open the RIME-LMDG Model's Github repository and download the latest version:
Mirror Acceleration Information
If you cannot access GitHub, or the download is too slow; then you can use the mirror acceleration provided by CNB (thanks to CNB for providing computing power and storage support; automatically synchronize the latest version of the RIME-LMDG Model:
Then, move the configuration file to the Rime configuration directory, such as the macOS Squirrel configuration directory: $HOME/Library/Rime/:
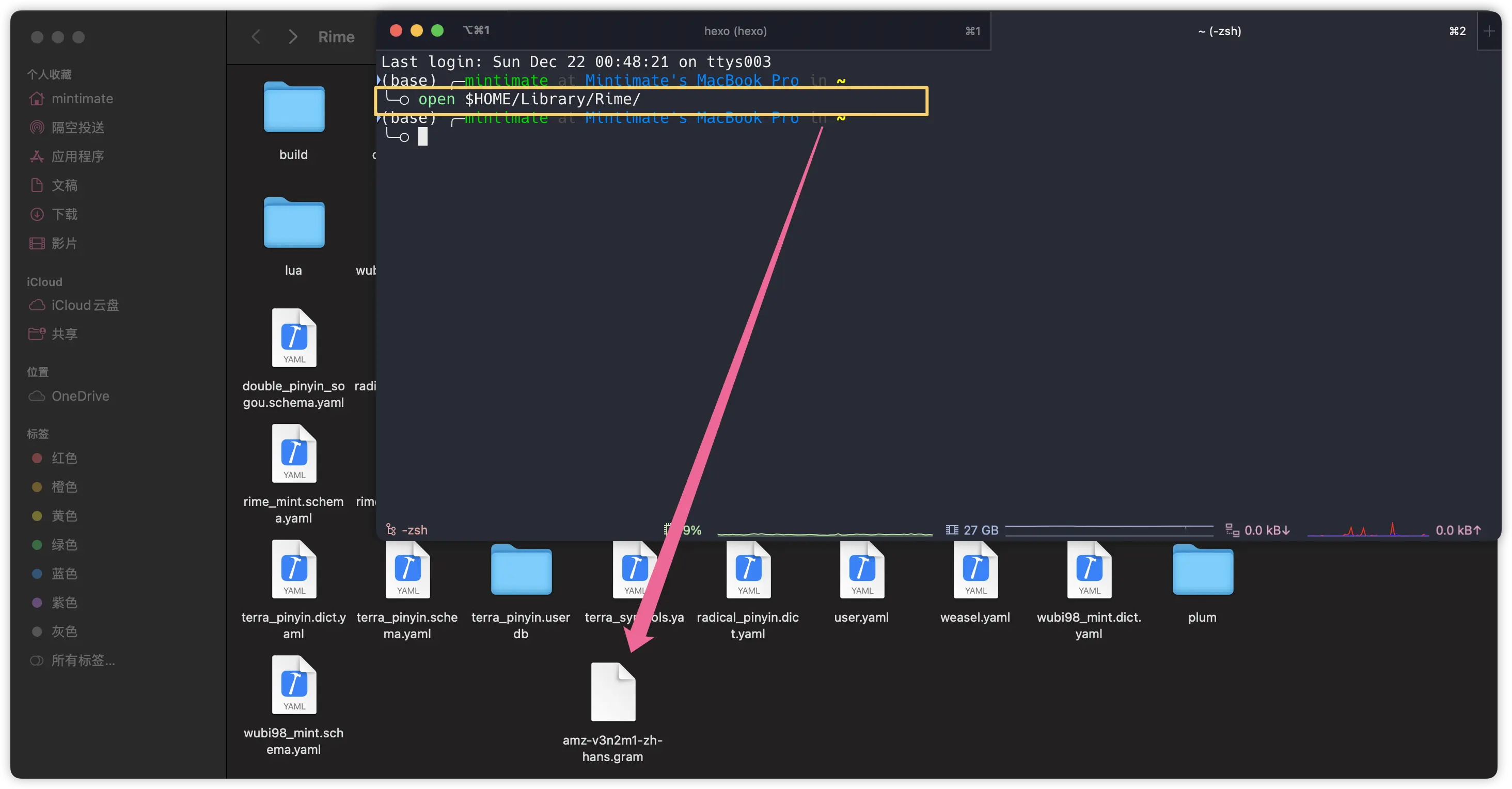
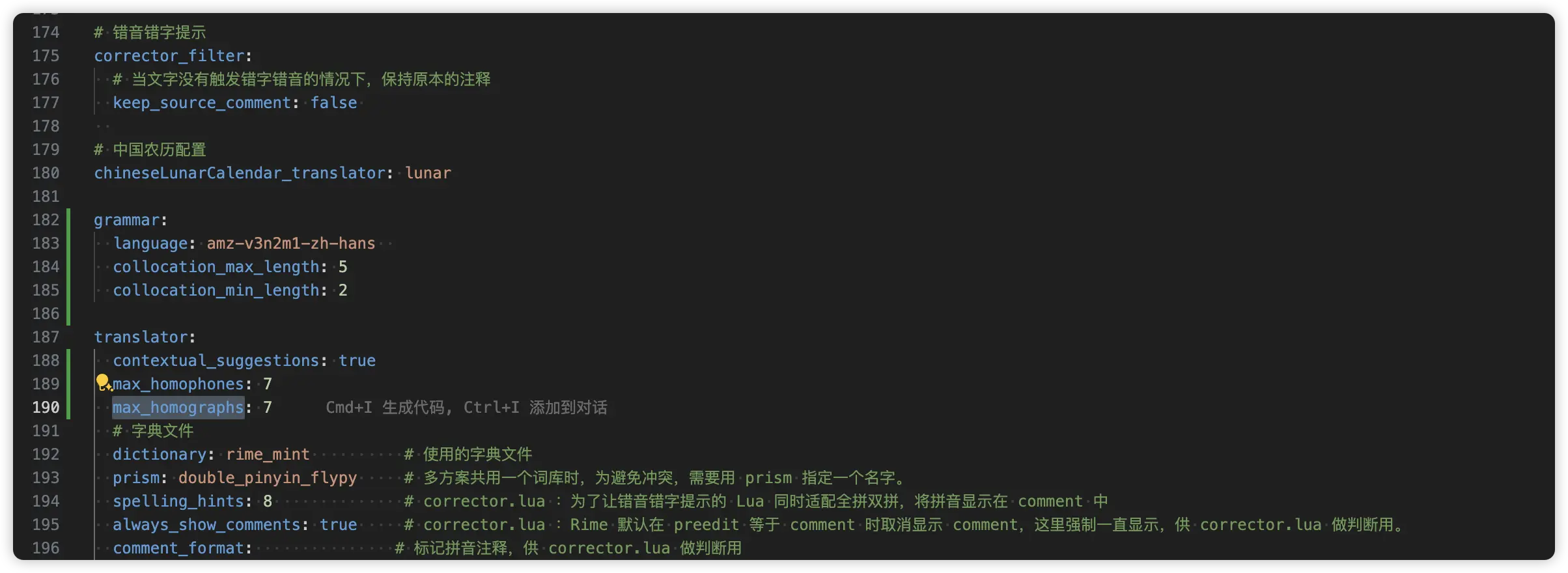
Here, the language model file we downloaded is: wanxiang-lts-zh-hans.gram, so if we want to use it in 薄荷全拼 (rime_mint), we can add it in rime_mint.custom.yaml:
Parameter Notes
As of 2026-05-21, the grammar parameters have been updated. Based on the author's corpus annotation and debugging, three parameters — collocation_penalty, non_collocation_penalty, and rear_penalty — have been adjusted for improved sentence- and character-level accuracy.
patch:
# Language model
"grammar/language": wanxiang-lts-zh-hans
"grammar/collocation_max_length": 8
"grammar/collocation_min_length": 2
"grammar/collocation_penalty": -16
"grammar/non_collocation_penalty": -8
"grammar/weak_collocation_penalty": -100
"grammar/rear_penalty": -20
# Load within translator
"translator/contextual_suggestions": true
"translator/max_homophones": 7
"translator/max_homographs": 7Finally, redeploy.
If you want to directly modify rime_mint.schema.yaml, you can modify it as follows:
Usage Recommendations
It is recommended for those who like to type long sentences to load the RIME-LMDG Model, as it provides more accurate recognition for long sentences.