Customizing Input Content
If you want to customize some content, this article provides some explanations.
It is recommended to use the following software to customize the content of this article:
This article refers to the following sources:
- Wusong Pinyin Documentation: https://dvel.me/posts/rime-ice
- Official Rime Customization Guide: https://github.com/rime/home/wiki/CustomizationGuide
Writing a Lexicon
Due to the design of Rime, English words and super simple abbreviations are not suitable in the Pinyin lexicon:
hello hello
世界 s j
蒙奇·D·路飞 meng qi d lu feiAs you can see, 世界 is represented by s and j, which will cause the input method to fail to suggest words or phrases starting with s. The same applies to j and d, which will result in the failure to suggest relevant words or phrases starting with j.
If all lexicons are designed in this way, when you input s, the input method will try to suggest all words or phrases starting with s, leading to lagging, memory leaks, and even crashes.
Therefore:
- It is recommended to use full Pinyin for all lexicon entries.
- English lexicons should be placed in the English dictionary. In the Mint input method, the English lexicon is used as the secondary input source, and automatic prediction and sentence generation for English input should be disabled.
When you examine the files in the Mint input method, you will find that the directory structure is as follows:
dicts
├── custom_simple.dict.yaml # Custom dictionary, where you can add your favorite words
├── luna_pinyin.biaoqing.dict.yaml # Emoji dictionary
├── luna_pinyin.emoji.dict.yaml # Emoji dictionary (may be removed in the future)
├── luna_pinyin.extended.dict.yaml # Extended dictionary for Luna Pinyin (may be removed in the future)
├── rime_ice.41448.dict.yaml # Extended single-character dictionary for Rime Ice
├── rime_ice.8105.dict.yaml # Basic single-character dictionary for Rime Ice
├── rime_ice.base.dict.yaml # Core basic lexicon for Rime Ice
├── rime_ice.en.dict.yaml # English dictionary for Rime Ice
├── se_words.dict.yaml # Commonly used lexicon for software industry
├── terra_rime_ice.base.dict.yaml # Earth Pinyin dictionary (generated by Python)
└── wubi98_base.dict.yaml # Wubi 98 dictionaryThe content of the lexicon files is written as follows:
---
name: Lexicon Name
version: "Version Number"
sort: by_weight (sort by weight) | original (sort in the order of the character table)
columns: # When columns attribute is not specified, the default order is:
- text # Vocabulary
- code # Code
- weight # Weight
- stem # Word-building code (not related to Pinyin scheme)
...
你好 ni hao 123
For lexicon files without phonetic annotation but with weight specified, modify the columns accordingly:
---For example, note that the format inside the lexicon is 'Word'<Tab>'Pinyin'<Space>'Pinyin'<Space>'Pinyin'<Tab>'Weight':
# Rime dictionary
# encoding: utf-8
#
# Personalized terms - by @Mintimate
# It is recommended to add custom phrases or words here
---
name: custom_simple
version: "2023.11.30"
sort: by_weight
...
# Personal names
# Common phrases
哈哈 ha ha 99
macOS mac 99
可以 ke yi 99
# (。>ㅅ<。)
Mintimate mintimate 1
https://www.mintimate.cn mintimate 2
Mintimate's Blog mintimate 3These lexicons are referenced by the lexicon driver configuration in the root directory:
├── custom_dict_en.all.dict.yaml # English lexicon for Mint input method
├── custom_dict_terra.all.dict.yaml # Terra Pinyin Mint custom lexicon
├── custom_dict.all.dict.yaml # Mint Pinyin lexicon
└── custom_dict.wubi.dict.yaml # Wubi 98 Mint custom lexiconLet's see how internal references are used:
---
name: custom_dict.all ## Note that the name should match the filename
version: "2020.6.7"
sort: by_weight
# This is where you specify the dictionaries used by the input method, to supplement the extended dictionary.
import_tables:
- dicts/rime_ice.8105 # Mist Pinyin common character collection
- dicts/rime_ice.41448 # Mist Pinyin complete character collection
- dicts/custom_simple # Custom
- dicts/rime_ice.base # Mist Pinyin https://github.com/iDvel/rime-ice
- dicts/se_words # Internet network vocabulary
- dicts/luna_pinyin.biaoqing # Emoticons
- dicts/luna_pinyin.emoji # Emoji Ext
...Important:
name: Thenameis the filename without the.dictextension, and the filename should end with.dict.import_tables: Enumerate the lexicons that need to be imported.
After modifying the lexicon, remember to redeploy the input method.
The above information can help you customize the lexicons.
Custom Text
"Custom Text" refers to the custom_phrase.txt file within the input method. You may not see it in the Mint input method...
In my understanding, "Custom Text" refers to lexicons with particularly high weights (this is the default behavior, but the weights of each translator can be adjusted using initial_quality). Therefore, I have removed the configuration for "Custom Text." If needed, you can configure it yourself. The format is the same as the lexicon:
# Rime table
# encoding: utf-8
# Custom Text
# Do not write any comments after this line
噷 hm
哼 hng
去 q 2
千 q 1
我 w 3
万 w 2
往 w 1
等等 dd
的地得 ddd
等等等等 dddd
刚刚 gg
才刚刚 cgg
知道 zd
不知道 bzdAlso, the input method configuration needs to include:
translators:
- table_translator@custom_phrase # Custom Phrase custom_phrase.txt
# Custom Phrase
custom_phrase:
dictionary: ""
user_dict: custom_phrase # Need to manually create custom_phrase.txt file
db_class: stabledb
enable_completion: false # Completion prompt
enable_sentence: false # Disable sentence making
initial_quality: 99 # The weight of custom_phrase should be larger than other lexiconCustom Text does not interact with other translators in word-building. If you use a complete code, the character or word cannot participate in word-building. That is, self-built words cannot be remembered.
Therefore, it is recommended to fix non-complete code characters or words. For example, '的'(de) should be 'd', '是'(shi) should be 's', and '仙剑'(xian jian) should be 'xj'.
Note that the full Pinyin 'a o e' is also a complete spelling, so single characters of 'a o e' should not be included in the Custom Text. Otherwise, words like '啊 哦 呃' cannot be used for word-building.
Using the full Pinyin input method within Oh-my-rime as an example, according to the Configuration and Overrides method, we can create the rime_mint.custom.yaml file:
# Rime Custom
# encoding: utf-8
patch:
"engine/translators/+":
- table_translator@mint_simple # Mint custom phrases
# Mint custom phrases
mint_simple:
dictionary: ""
user_dict: dicts/rime_mint.simple
db_class: stabledb
enable_completion: false
enable_sentence: false
initial_quality: 0.5
comment_format:
- xform/^.+$//At the same time, we need to create the dicts/rime_mint.simple.txt file:
# Rime table
# coding: utf-8
#@/db_name rime_mint.simple.txt
#@/db_type tabledb
#
#
# No comments can be written after this line
我们 wmNote that the content within the rime_mint.simple.txt file follows the format of 「phrase」<Tab>「Pinyin abbreviation」.
Finally, after redeploying the input method, you will be able to see the effect of the custom text.
Double Pinyin Convert
By default, the Mint input method performs a conversion for the candidate area code in double pinyin. For example, when you need to spell "你好" (Hello) in DoubleFly pinyin, it will appear as "nihao" instead of "nihc".

Actually, this is due to the translator/preedit_format configuration in the scheme. This configuration is used to escape the code. Let's take DoubleFly pinyin as an example:
translator:
preedit_format:
- xform/([bpmfdtnljqx])n/$1iao/
- xform/(\w)g/$1eng/
- xform/(\w)q/$1iu/
- xform/(\w)w/$1ei/
- xform/([dtnlgkhjqxyvuirzcs])r/$1uan/
- xform/(\w)t/$1ve/
- xform/(\w)y/$1un/
- xform/([dtnlgkhvuirzcs])o/$1uo/
- xform/(\w)p/$1ie/
- xform/([jqx])s/$1iong/
- xform/(\w)s/$1ong/
- xform/(\w)d/$1ai/
- xform/(\w)f/$1en/
- xform/(\w)h/$1ang/
- xform/(\w)j/$1an/
- xform/([gkhvuirzcs])k/$1uai/
- xform/(\w)k/$1ing/
- xform/([jqxnl])l/$1iang/
- xform/(\w)l/$1uang/
- xform/(\w)z/$1ou/
- xform/([gkhvuirzcs])x/$1ua/
- xform/(\w)x/$1ia/
- xform/(\w)c/$1ao/
- xform/([dtgkhvuirzcs])v/$1ui/
- xform/(\w)b/$1in/
- xform/(\w)m/$1ian/
- xform/([aoe])\1(\w)/$1$2/
- "xform/(^|[ '])v/$1zh/"
- "xform/(^|[ '])i/$1ch/"
- "xform/(^|[ '])u/$1sh/"
- xform/([jqxy])v/$1u/
- xform/([nl])v/$1ü/
- xform/ü/v/ # ü 显示为 vIf you don't need it, you can overwrite the translator/preedit_format configuration in the scheme to be empty. For example, in the case of DoubleFly pinyin, we can create a double_pinyin_flypy.custom.yaml file:
# Rime Custom
# encoding: utf-8
patch:
translator/preedit_format: []After that, redeploy the input method, and you can see the double pinyin code.
Note
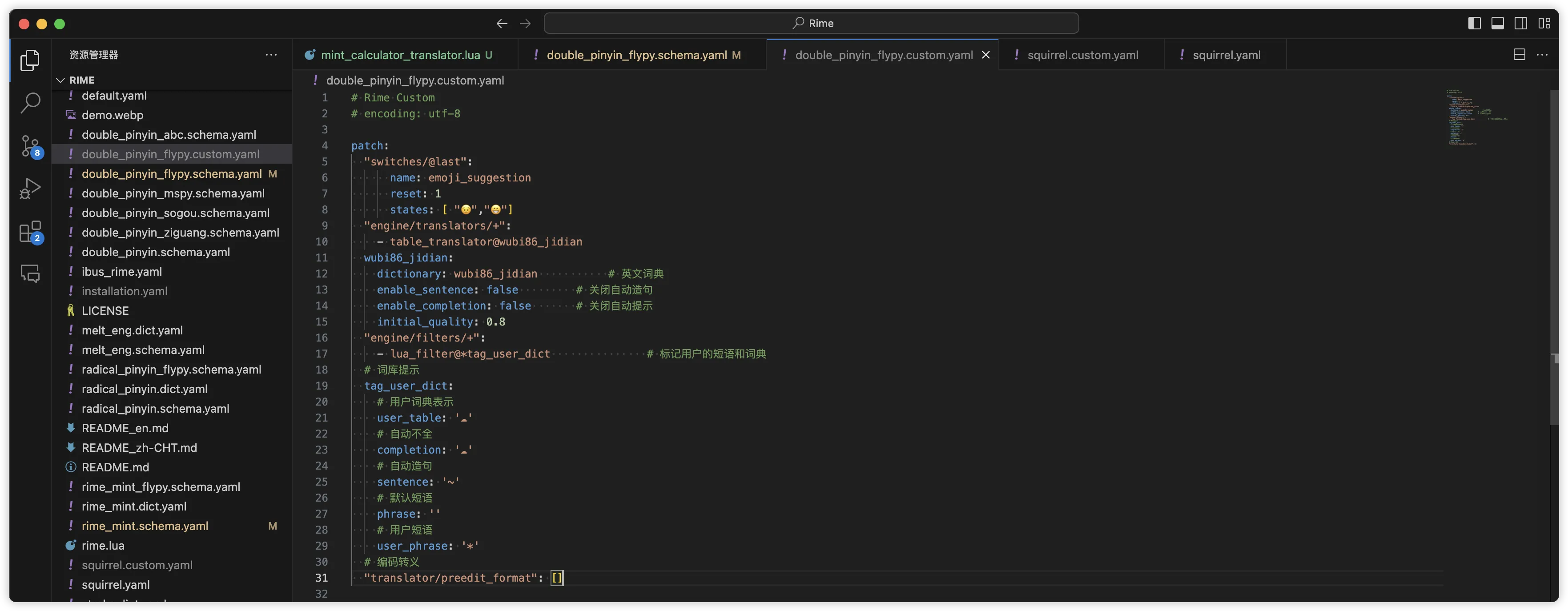
In a custom file, there can only be one patch entry. For example, if I have overwritten other configurations, then the custom file might look like this:
# Rime Custom
# encoding: utf-8
patch:
"switches/@last":
name: emoji_suggestion
reset: 1
states: [ "😣️","😁️"]
"engine/translators/+":
- table_translator@wubi86_jidian
wubi86_jidian:
dictionary: wubi86_jidian # English dictionary
enable_sentence: false # Turn off automatic sentence making
enable_completion: false # Turn off automatic prompts
initial_quality: 0.8
"engine/filters/+":
- lua_filter@*tag_user_dict # Mark user's phrases and dictionaries
# Dictionary prompts
tag_user_dict:
# User dictionary representation
user_table: '☁'
# Auto full
completion: '☁'
# Auto sentence making
sentence: '~'
# Default phrase
phrase: ''
# User phrase
user_phrase: '*'
# Code escape
translator/preedit_format: []